
 |
| Mooie scheiding van de celkernen. |
Ik train met een U-model neuraal netwerk dat ik overneem uit dit voorbeeld. Vreemd genoeg krijg ik foutmeldingen. Een heeft te maken met de 'mean_iou functie' die bijgevoegd is om de meting volgens de competitie evaluatie te bepalen.
Failed to convert object of type <class 'theano.tensor.var.TensorVariable'> to Tensor.
De auteur geeft echter aan dat deze waarschijnlijk nog niet correct is dus die kan ik verwijderen. De 2e melding is een Keras melding dat in de Conv2DTranspose functie een 'even aantal' in de matrix niet ondersteund wordt bij padding='same'.
ValueError: In `Conv2DTranspose`, with padding mode `same`, even kernel sizes are not supported with Theano. You can set `kernel_size` to an odd number.
Het wordt mij niet duidelijk waarom het model in het voorbeeld wel werkt en bij mij niet. Ik maak daarom een aanpassing van 2x2 naar 3x3. Ik zie nu dat ik dat ook voor de Conv2D layers zelf heb gedaan. Wellicht wat overbodig. Ik zet deze terug naar 2x2. Ben benieuwd naar het effect later.
Het trainen van het netwerk neemt zoals gebruikelijk meerdere dagen. Het lukt gelukkig vrij snel om de test afbeeldingen in delen van 80x80 aan te bieden, te evalueren, en vervolgens weer samen te stellen. De resultaten lijken aardig.

 |
| Een 'artefact' |
 |
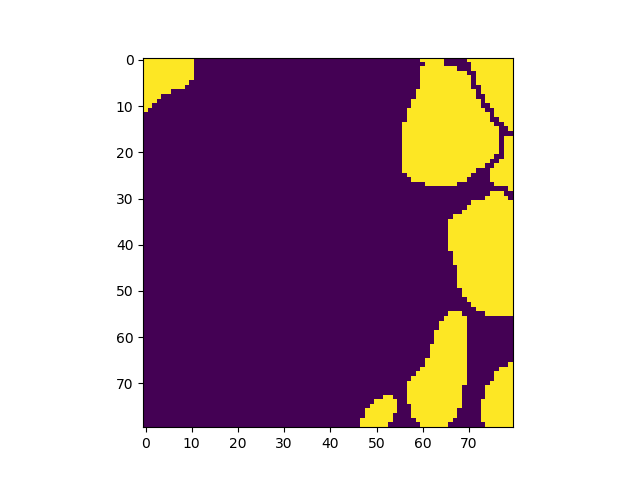
| Hier lijkt het model nog verre van goed. De celkernen worden lang niet allemaal herkent. Maar ook zie je de 80x80 grenzen hier en daar terug. Met als sterkste natuurlijk het gele vierkant. |
 |
| Vreemd dat de gele vierkanten soms blijven terugkomen. Wellicht een gebrek aan basis informatie. |
 |
| Hoewel overall redelijk blijven ook hier de overgangsgebieden van de 80x80 'vensters' zichtbaar |
Ik besluit de resultaten toch maar aan te bieden. Dan is dat deel iig ook eens getest. Het lukt goed maar nog met een relatief lage score. Om e.o.a. reden zijn, gek genoeg, de dropout layers uit mijn model verdwenen. Omdat ik veel vergelijkbare afbeeldingen heb is het inbrengen van dropout denk ik nog belangrijker om het systeem robuuster te maken en de kans op overfitting te verminderen.
 |
| Valt altijd tegen de eerste submissies ... Het voorbeeld model had al veel een hogere waarde: LB 0.277 |
Geen opmerkingen:
Een reactie posten